G検定を受けるにあたり、用語を整理する。自分の学習用である。
- あ~
- か~
- さ~
- た~
- な~
- は~
- ま~
- や~
- ら~
- わ~
- A~G
- H~L
- M~R
- S~Z
あ~
アンサンブル学習
複数の機械学習モデルを組み合わせて、より高い精度の回答を得る手法のことを指す。
バギング
重複ありでサンプルを抽出し複数に分散して、並列で学習を行い統合する手法
ブースティング
弱い学習器を直列で配置して、次々と学習しその結果を組み合わせて最終的に強固な学習器とする手法。
スタッキング
直訳すると「積み重ね」となる。複数段階に分けて学習を行う。
第一層ではバギングやブースティングにより様々なモデルを生成する。
第二層ではそれらを統括したメタモデルにより分析を行う。
場合によっては第三層にてさらに分析を深める。
オートエンコーダ
ニューラルネットワークの1つ。入力されたデータを一度圧縮し、重要な特徴量だけを残した後、再度もとの次元に復元処理をするアルゴリズムを意味する。下記の図のようにエンコードが「次元圧縮」で、デコードが「次元復元」という役割になる。

オートエンコーダ(自己符号化器)とは|意味、仕組み、種類、活用事例を解説 | Ledge.ai
変分オートエンコーダ(VAE)
オートエンコーダのデコーダに変数を混ぜて、入力とは異なる出力を行うもの。生成モデルとしても知られている。データの圧縮と復元に加えて、入力データを圧縮して得られる特徴ベクトル(潜在変数)を、確率変数として表すことが可能である。
オントロジー
人間の持つ「情報」をコンピュータが分かるように整理、記述すること、またそのフレームワーク自体を指す。一般的にはツリー構造で表すことができる。

AI/IoT時代に「オントロジー」が注目される理由──JDMC理事 北澤氏に聞く (1/4)|EnterpriseZine(エンタープライズジン)
か~
カーネルトリック
学習データに含まれる特徴ベクトルを高次元に非線形変換して、その空間で線形の識別を行う機械学習の手法をカーネル法と呼ぶ。サポートベクターマシンにおいてより明確に分類をできるようにするために、あえて高次元化するわけである。
具体的には円状にデータが散布しており、直線で分離ができない場合、3次元に見立てて平面で分離をするような場合である。この際に計算量を抑えるための手法がカーネルトリックとなる。
画像セグメンテーション
セマンティックセグメンテーション
画像全体や画像の一部の検出ではなく、ピクセル(画素)単位で被写体などのタグ付けやカテゴリ分けを行う。
物体が重なっていると各々の区別は難しいものの、空や道路など不定形の領域を検出可能となっている。自動運転車や個人のスマホ、製造工場や医療現場まで現代の幅広いシーンにおいて、被写体を識別してメリットを得る作業に活用されている。
インスタンスセグメンテーション
画像の中にある物体の領域を特定した後で個体ごとに領域分割し、物体の種類を認識する手法。物体ごとの領域分割と、物体の種類の認識の両方を実行する。
不定形の領域は不向きですが、セマンティックセグメンテーションが苦手とする隣接した物体を区別可能となる。
パノプティックセグメンテーション
セマンティックセグメンテーションとインスタンスセグメンテーションを組み合わせた方法。画像内のすべてのピクセルにタグが付けられ、カウントできる物体として個別認識した結果が返される。
パノプティックセグメンテーションでは、2つのセグメンテーションが持つ長所をつなぎ合わせることで、スムーズに画像認識が可能となる。
機械学習
データから、「機械」(コンピューター)が自動で「学習」し、データの背景にあるルールやパターンを発見する方法。近年では、学習した成果に基づいて「予測・判断」することが重視されるようになった。
教師あり学習
入力データと、出力データ(答)が揃っており、入力データから出力データを推計するためのもの。入力と出力の関係を分析するためには、統計学の手法である回帰分析を、機械的にすべてのデータの組み合わせで実施する方法などがある。代表的な例としては、天候、価格、販促などの要因から売上を予測するなど。
大きく分類と回帰に分けることができる。
分類
分類の主な目的は、データが属するクラス(Yes,Noのような)を予測することとなる。特に、予測するクラス数が2クラスの場合2値分類と呼ばれ、3クラス以上の場合は多項分類と呼ばれる。
具体例としては、ある学生のプロフィールを入力としてその学生が合格か不合格かを予測する、顧客の購買情報からその顧客が新商品を買うか買わないかを予測するような場合である。
多項分類においてはマルチクラス分類とマルチラベル分類がある。マルチクラス分類は、果物の画像からリンゴ・バナナ・ぶどうなど、3つ以上の結果について分類を行う。マルチラベル分類は例えばある新聞記事について、政治・経済・国際といったラベルに割当をするような場合である。
回帰
回帰の主な目的は、連続値などの値の予測となる。具体例としては、広告予算の増加による商品の売り上げの増加予測などである。線形回帰()、多項式回帰(
)など。
教師なし学習
一連の入力データから、データの背景にある隠れたパターンや構造を見つけ出すもの。「教師あり学習」と比べると、目的となる変数(出力データ)がないため、各データ間の近さや類似度などを計算して、データをグループに分けたり、データ間のつながりを推計する。
統計学では使われないクラスタリング手法が使われることが多く、代表的な例としては、ネットショッピングにおけるレコメンデーションを行うロジックなどが挙げられる。
強化学習
教師あり・なし学習とは異なり、最初からデータがあるわけではなく、システム自身が試行錯誤しながら、精度を高めていくための学習方法。現在の状態を観測し、得られる収益(累積報酬)を最大化するために、どのような行動をとるべきかを決定する機械学習の一分野である。
例えば、ロボットの歩行距離を伸ばすためにはどうすればよいかを考える際に、入力データから歩行距離を推計するのではなく、ロボットが歩行距離を伸ばすために自ら新たな歩き方を試行錯誤し、その結果を学習しながら最適な歩き方(アルゴリズム、ルール)を見出す方法。自ら試行錯誤しながら学んでいくという点がポイントとなる。
強化学習とディープラーニングの違いは、「学習過程で人間の指示を必要とするかという点にある。強化学習では、AIが何を学習するかを決めるのは人間であり、あらかじめ学習するデータを与えなければならない一方、ディープラーニングは与えられたデータを参照して自ら学習すべき要素を発見し、試行錯誤を繰り返す。近年では、強化学習とディープラーニングを掛け合わせた「深層強化学習」という学習方法も登場している。
強化学習における用語は以下の通りである。
エージェント
強化学習を行う当事者のこと。例えば、AIに対して強化学習を行う場合は、「エージェント=AI」となる。エージェントは「環境」に対して「行動」を起こし、その結果によって「報酬」を得る流れを繰り返しながら、最適な行動を学んでいく。
環境
「エージェントが行動を起こすための土壌」のこと。「エージェントに与えられた前提条件」とも表現できる。エージェントは、与えられた環境の中で行動を起こして報酬を獲得し、学習を行う。
状態
エージェントが現在置かれている状況のこと。言い換えれば、「エージェントの現在地」とも表現できる。エージェントは、新たな報酬を得るために、現在の「状態」から次の行動を起こす。すると、現在の「状態」は別の値に変化する。
行動
「エージェントが起こすアクション」のこと。例えば「歩く」「走る」のような、具体的なアクションを指す。エージェントが行動を起こすと「環境」から「報酬」が与えられて、「状態」が変化する。
報酬
エージェントが起こした行動によって「環境」から付与される値。エージェントがなんらかの行動を起こすと、その結果、今までにはなかった変化が起こる。この「変化」を数値化したものが、「報酬」となる。
Q学習
ある行動を取るたびに「Qテーブル」にその行動の価値(Q値)を入力し、新しく行動するたびに値を更新する学習方法。「Qラーニング」と呼ばれることもある。Q学習では、新たな行動を繰り返すことでQテーブルを埋めていき、「その時点で価値を最大化できる行動」をAIに学ばせる。
Qテーブルの値は、試行錯誤を繰り返して更新されるたびに信頼性が高まる。テーブルが埋まった状態で、最も高いQ値を示す行動が、最もよい報酬を得られる行動であると考えられる。
Sarsa
「S(現在の状態)」「A(エージェントの行動)」「R(報酬)」「S’(行動後の状態)」「A’(行動後の状態から判断した、エージェントの次の行動)」の5つの要素から構成される学習方法。
現在の状態からエージェントがある行動を取ったとき、エージェントには行動に対する報酬が与えられる。その結果、「S’」という行動後の状態が確定する。その後、エージェントは「S’」という状態を前提にして、「A’」という次に取るべき最適な行動を予測し、次の行動に移る。この流れを繰り返すことでAIが最適な行動パターンを学ぶのが、Sarsaの特徴となる。
モンテカルロ法
「エージェントの行動の結果、どのような報酬が与えられるか不明な状態」に効果的な学習方法。モンテカルロ法では、エージェントにある行動を完遂させることで得られる報酬を、「エピソード」の形で順番に記録していく。その後、得られた報酬の平均を算出して、それぞれのエピソードが起こる期待値を割り出し、その値をAIに与える強化学習の際の「報酬」として活用する。
クラスタリング
ある集合を何らかの規則によって分類すること。教師なし学習において、データに対して特徴を見出し、自動で分類を行う。
階層クラスタリング
樹形図として表せるられるクラスタリングである。最も似ている(もしくは似ていない)サンプル同士を1つずつ順番にグルーピングしていくことで、すべてのデータがグルーピングされるまで繰り返し、最終的にひとつの樹形図を完成させる。またこの樹形図のことをデンドログラムという。

クラスタリングとは?手法やメリット・デメリット、サーバクラスタリングの目的を徹底解説 | ビジネス継続とITについて考える
非階層クラスタリング
階層を作らずにデータをグルーピングしていく手法。母集団の中で近いデータをまとめて、指定された数のクラスタに分類していく。非階層クラスタリングでは事前にクラスタ数を決めて指定しておく必要がある。(本記事k-means法参照)
ハードなクラスタリング
各データが1つのクラスのみに所属するようなクラスタリング。例えばいろんな人種の写真において、Aさんは日本人、Bさんはアメリカ人、Cさんはアフリカ人というように分ける場合。
ソフトなクラスタリング
各データが複数のクラスタに所属することを許すようなクラスタリング。 例えばいろんな人種の写真において、Aさんは日本人80%・アメリカ人20%、Bさんはアメリカ人60%・日本人40%、Cさんはアフリカ人90%・アメリカ人10%のような場合。
交差検証
標本データを分割し、その一部をまず解析して、残る部分でその解析のテストを行い、解析自身の妥当性の検証・確認に当てる手法を指す。交差検証法では訓練データとテストデータを交差させ、それぞれの評価の平均を取得することでより正しい推定値を獲得する。イメージは以下のような図である。
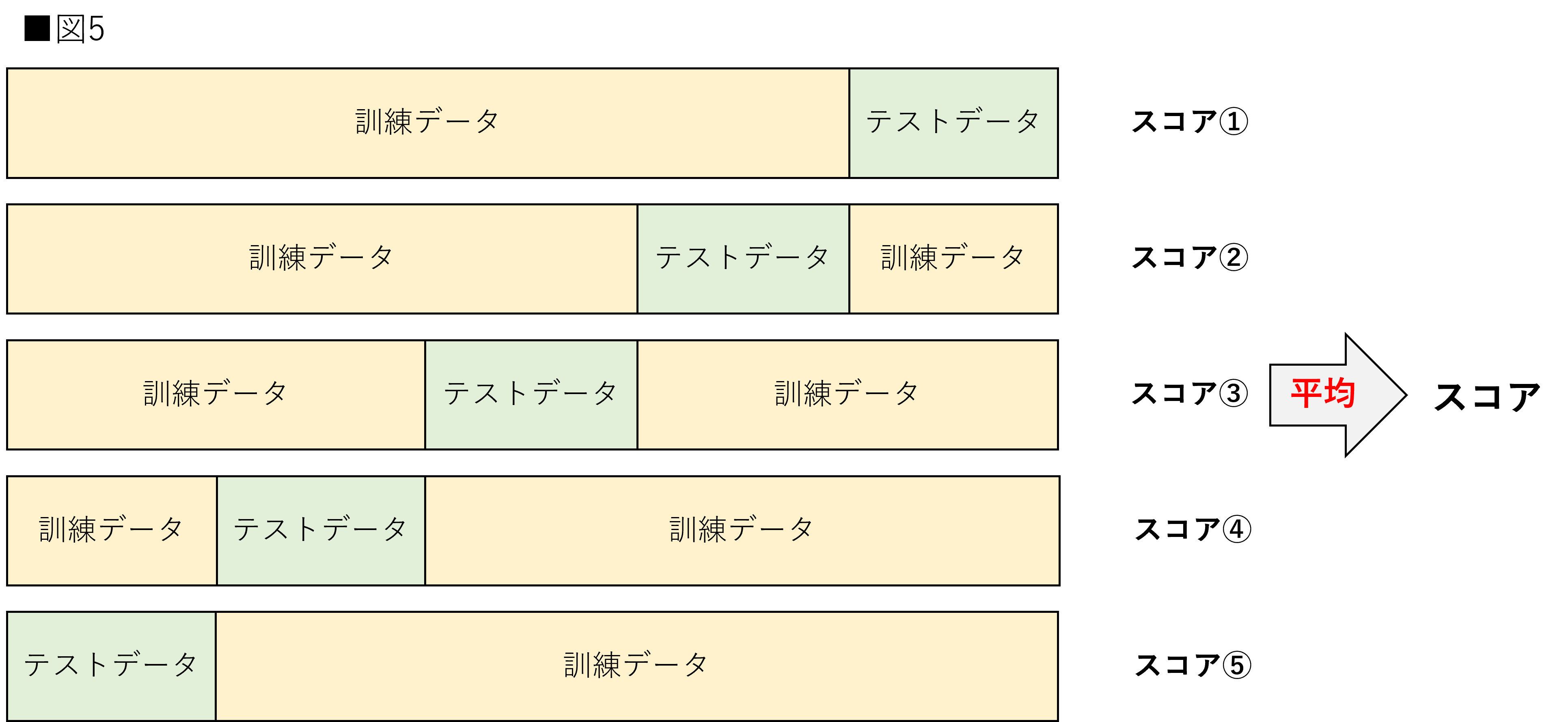
交差検証(Python実装)を徹底解説!図解・サンプル実装コードあり
ホールド・アウト法
全訓練データを 3 つのサブセットに分ける方法である。すなわち、あらかじめ、全訓練データを、モデルを学習用、ハイパーパラメーターの組み合わせ評価用、そして最終的な汎化性能評価用の 3 つのサブセットに分けてから、最適なモデルを構築していくことになる。これらのサブセットを訓練データ(trainig data)、評価データ(validation data)、そしてテストデータ(test data)と呼ぶ。
交差検証と異なり、訓練データとテストデータを交差して平均する、ということはしない。
一つ抜き法
k分割交差検証の個々の分割が、1個のデータのみをテスト用に利用し、残りを全て学習データとして利用する交差検証方法。
勾配降下法
損失関数において最適解を求めるための方法。損失関数においては二乗誤差のように二次関数で表せられることが多いため、微分をして最小値を求めることで誤差が最小=最適解となる。ただし、損失関数が四次関数となると、極小値と最小値をもつ可能性があり、極小値の方を最適解と誤認してしまう可能性がある。
数式的には以下となる。
損失関数Eの微分値(∇E)に学習率(η)をかけて重み(w)更新していく。
勾配降下法(最急降下法)のステップとしては以下の通り。
1.ある重み(w0)にて損失関数を求める。このときの損失関数の値が最小であるかを考える。
2.損失関数をwで微分し、w0を代入した値(微分係数)を算出する。
3.損失関数が下に凸の二次関数の形状であることを前提とすると、微分値・微分係数(導関数の傾き)が負であればw0は最小値より左側にあり、正であればw0は最小値より右に位置していると言える。
4.上記数式により、損失関数の微分値に学習率をかけた重みwの更新をする。例えば微分値が負であればマイナスの微分値を引くことになるので、新しい重みは右側に移動していく。正であれば当然逆である。ここで、学習率が大きければ重みwを大きく変えることになるし、小さければ少しずつ変えることとなる。
5.これらを繰り返して損失関数の微分値が0となるようなwを探し出す。これが最適解となる重みとなる。
確率的勾配降下法(SGD)
学習データの中からランダムに 1 セットだけを取り出して損失を計算する。これにより、すべてのデータをメモリ上に読み込む必要がなく、一度に 1 セットのデータでしか損失を計算しないので、最急降下法に比べて必要な計算リソースは少なく、計算速度が速い。また、確率的勾配降下法は、最急降下法に比べて局所最適解に収束する可能性は少ない。
ミニバッチ勾配降下法
深層学習などでは、ミニバッチ勾配降下法を使用している。確率的勾配降下法では、損失を計算するのに、学習データのうち 1 セットのデータだけを使っている。これに対して、ミニバッチ確率的勾配降下法では、学習データの中からランダムに b 個のデータを取り出して、損失を計算している。このときに取り出した個数をバッチサイズという。
勾配ブースティング
「ブースティング」とは、与えられたデータから決定木分析を行った後に、予測が正しくできなかったデータに重みをつけて、再度、決定木分析を行い、これを繰り返すことで精度を高める方法。(弱学習器を順番に学習することで制度を高めるアンサンブル学習)
さらに、データに重みづけするのではなく、予測値と実績値の誤差を計算し、誤差を決定木で学習する方法が「勾配ブースティング」となる。ブースティングと同様に、誤差に対する学習を繰り返すことで精度を高めていく。
※決定木による勾配ブースティングを勾配ブースティング木と呼ぶ。決定木以外のアルゴリズムでも勾配ブースティング自体は可能。
誤差逆伝播法
モデルに入力を与えて得られた出力とそれに対応する正解ラベルの誤差を求めたあと、その誤差を微分の連鎖律に基づいて出力側から入力側に逆伝播することで、各層のパラメータに関する勾配を計算する枠組み。
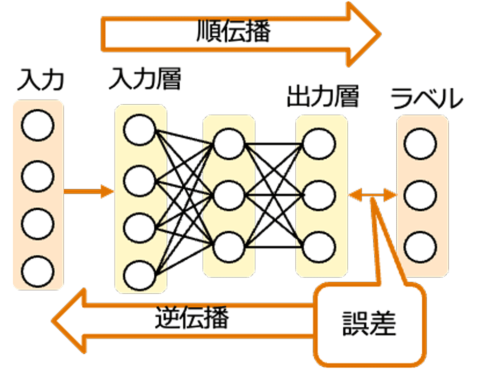
誤差逆伝播法を用いない深層ニューラルネットワークの学習方法:日経クロストレンド
ニューラルネットワークにおいてその妥当性を評価するには、出力した情報と本来の実測値の差分(損失関数)を取り、この差分をいかに小さくしていくか、が必要となる。それにあたり調整するのは入力情報における重みである。この値を調整して最終的な出力結果の精度を上げていきたいわけである。
ここで、重みをどれほど変えればどれほど出力結果に影響が出るか、を考えるには損失関数Eをwで微分すれば良いであろう。これを勾配という。
これを元にして重みwを更新することとなる。つまり以下のように表せられる。
仮に勾配が正であれば、wが増えればその分損失関数Eも増えることになるため、Eを抑えるにはwを減らす必要がある。
勾配消失問題
誤差逆伝播法の際に層が深いニューラルネットワークにおいて、重みが何度も更新されることによって勾配がほぼ0になってしまい、学習が上手くいかなくなる問題。
上記のを求めるに当たって、右辺の勾配部分がほぼ0となると、結局重み
はほぼ変わらなくなってしまうのである。
これが発生する原因としては、例えばシグモイド関数の微分値は必ず1より小さくなるという性質に起因する。ニューラルネットワークの層が深い場合には活性化関数の計算が何度も発生するので、誤差逆伝搬において、その微分値を掛け合わせる回数も必然的に多くなり、その結果勾配が消失するのである。
これを回避するために、シグモイド関数をtanh関数やReLU関数に置き換える必要がある。
コールドスタート問題
登場したばかりの新商品はユーザの行動履歴を元にしたレコメンドができないという問題。(もしくは新規登録したユーザーには検索履歴・行動履歴が無いため、そのユーザーに対するレコメンドができないという問題)
混同行列
モデルの予測と実態を対比し、アルゴリズムの性能を可視化するための特有の表配置である。誤差行列(error matrix)とも呼ばれる。
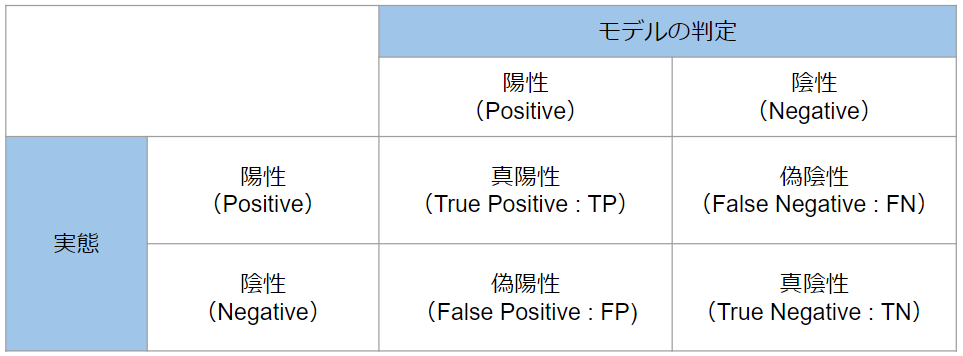
【わかりやすく解説】混同行列の概要をかみくだいて説明します - DXコンサルの日進月歩奮闘記
これを元に以下の指標で評価を行う。
正確率
予測が正しく行われた割合である。
基本的には正解率が高いモデルは良いモデルだが、必ずしも正解率が高ければ良いとは言えない。というのも、例えば感染率が0.01%の極めてかかりにくい病気があるとして、何でもかんでも健康判定してしまうガバガバな判定モデルで検査をしても、その正解率は99.99%を叩き出してしまうためである。
再現率
実態が陽性であるものの中で、モデルが陽性だと判定した割合である。
上記例において、ガバガバ判定モデルを使った場合再現率は0%となるであろう。(陽性判定すべきところでできていない。)このように再現率を用いることで正解率の罠を回避することができる。
他方で、再現率をあげようとすると、なるべく陽性判定を出すようなモデルに寄ってしまう。「本来病気の人を見落とすくらいなら陽性判定出したほうがよい」と考えるのであれば、再現率を高めるのを指標としても良いであろう。
適合率
モデルが陽性だと判定したものの中で実態が陽性だったもの割合である。
上記例で言えば、本当はその病気にかかってないのに陽性判定してしまった場合は適合率が下がってしまうことになる。つまり、「本来病気の人を見落とすくらいなら陽性判定出したほうがよい」をやりすぎると適合率が下がってしまうトレードオフの関係となる。陽性判定が出やすくなったあまり、二次検査の費用や手間が過剰に発生してしまうことを抑えるのであれば適合率を高めていく(偽陽性を抑える)必要がある。
F値
再現率と適合率の平均値(数学的には調和平均)である。
なお、調和平均そのものの定義は以下の通りである。
第一種過誤
偽陽性のこと。「個人は病気ではない」のにもかかわらず「個人が病気である」と判断してしまうことに相当する。
第二種過誤
偽陰性のこと。先ほどの例で言えば「個人が病気である」のに「個人は病気でない」と判断してしまう事に相当する。
さ~
サポートベクターマシン
機械学習の種類のうち、「教師あり学習」における「分類」のタスクで主に使用される。少ない教師データを使ってスピーディな計算が可能で、高い汎化性があることなど使い勝手が良いことなどが特徴。
あるクラスのデータ点を、別のクラスのデータ点から、可能な限り分離する超平面を見つけることで分類を行う。例えば2次元平面において、分類Aと分類Bを切り分ける直線(サポートベクタ)について、そこからの最大のマージンを持つように最適化を行う。
https://zero2one.jp/ai-word/support-vector-machine/
次元削減
データの次元を削減すること。例えば2次元平面の点について射影をして一次元へと落とすこと。


30分でわかる機械学習用語「次元削減(Dimensionality Reduction)」 #機械学習 - Qiita
このように多次元のデータについて次元を落とすことで計算量を減らすことができる。
上記例で言えば体重・身長はほぼ正比例の関係があるので、例えば身長・体重を用いて体育の成績を予測したい場合には、わざわざ体重と身長2つのデータが無くとも射影した情報があればそれを表すことが可能である。
自動運転レベル
【レベル0】運転自動化なし
ドライバーが全ての運転を行う従来の自動車。アンチロック・ブレーキシステム(ABS)や前車走行通知などが搭載されている車でも、運転操作に介入しないシステムのみの場合は、レベル0に該当する。
【レベル1】運転支援
自動ブレーキや前方の車両に追従するアダプティブ・クルーズ・コントロール(ACC)、車線維持のレーンキープアシストシステム(LKAS)など、ステアリングか加減速のいずれかを操作する機能が付いている車両で、ドライバーが運転操作の主体なのは変わりない。
【レベル2】部分運転自動化
レベル2は、レベル1のいくつかの機能を同時に行える他、高速道路など特定の条件のもとでは自動運転モードが使用できる車両。自車線内の歩行者やとっさの障害物など、まだ人の操作が必要となるシーンも多く、「運転支援車」に分類される。レベル1と同様、運転の主体はあくまで人間であり事故の責任は運転者となる。
【レベル3】条件付運転自動化
レベル3の車は、決められた走行環境や場所など条件は限定されるが、全ての運転操作を自動システムで行える機能を備えている。
レベル3以上になると、運転の主体は自動運行装置(装置の作動困難時は運転者)に変わり、自動運行中に事故が発生しても運転者の過失は問われない。
ただし、自動運行装置が正常に作動できない場合は、システムから手動運転への切り替えが必要になるため、常に運転可能な人物が乗っている必要があり、飲酒も厳禁となる。
【レベル4】高度運転自動化
レベル4の高度運転自動化車両は無人運行を前提として、決められたエリア、道路、天気、時間帯などの「運行設計領域(ODD)」を自動走行する。
システムがあらかじめ設定された環境を認識して走るため、運転操作が一切不要となる。また、不測の事態でも機能を維持できるようにシステムの冗長化がとられており、故障した場合も自動運転を続行できる。
【レベル5】完全運転自動化
レベル5は、レベル3、4のような特定の条件や運行設計もなく、自動運行システムが全ての運転操作を行う、ドライバー不要の車両を指す。運転が困難になれば自動で路肩へ寄り停車するなどの判断をするような機能まで求められる。
主成分分析
相関のある多数の変数から、相関のない少数で全体のばらつきを最もよく表す主成分と呼ばれる変数を合成する多変量解析の一手法。
図のイメージは以下の通り。
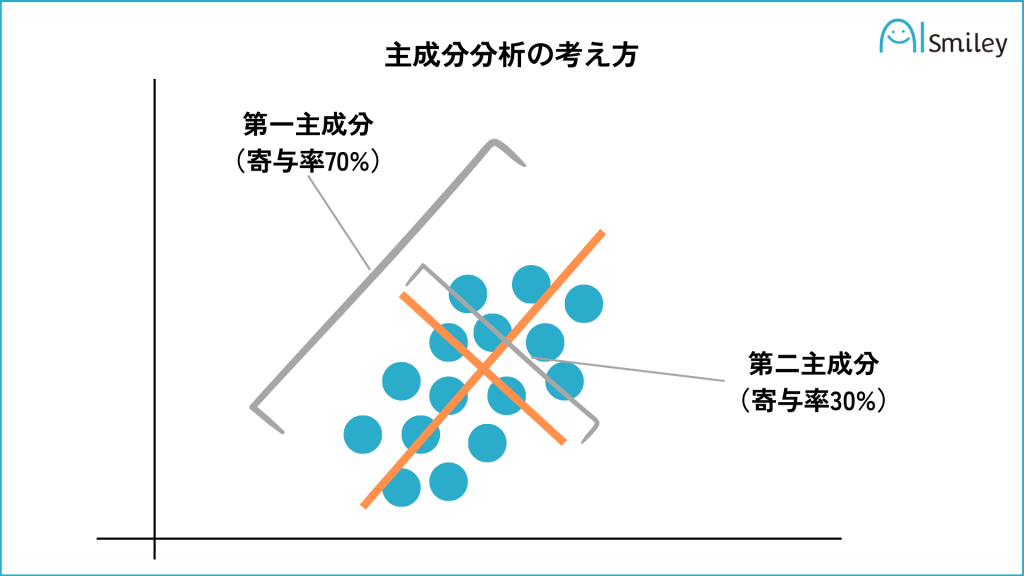
主成分分析(PCA)とは?機械学習での活用例や固有値などについて解説
簡易的にするために2次元平面で考える。あるデータに対して、主成分と呼ばれる直線(第一主成分)を定義する。そのうえでその直線に直角となる直線(第二主成分)を定義する。
2次元平面においては、この2つの直線の範囲(面積)ですべてのデータが包含されることになる(寄与率は合計で100%となる)が、例えばこれが3次元空間として考えた場合、第二主成分まででは寄与率が100%とはならないであろう。もっというと機械学習における多変量解析においては数十次元・数百次元を扱うことになるが、そういった中で最も累積寄与率が高くなるように主成分(直線)を選定することで、情報損失を抑えて次元削減することができることになる。
主成分の選定においては、主成分(各点)の分散が最大となることが条件となる。どういうことかというと、上記図でいうと第一主成分のオレンジ色線を数直線と見立てた場合、各点は一番端から端までの幅までレンジが持てているということになる。そして第二主成分はその垂直方向に対して同様のことが言えているということになる。図で表すと以下である。
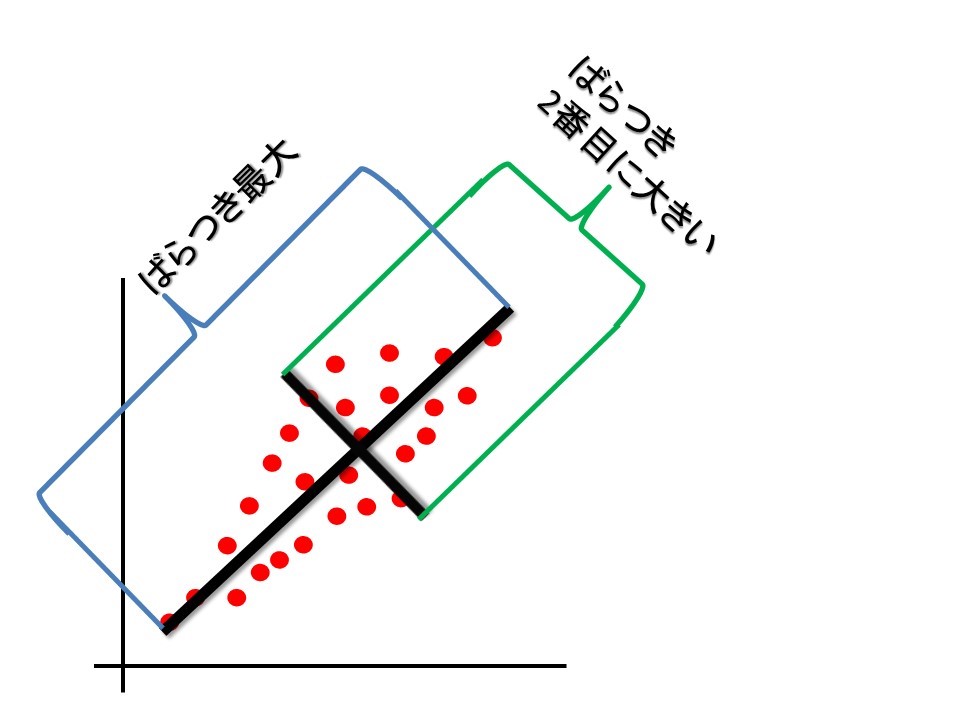
主成分分析とは? 例を使って活用方法とメリットをわかりやすく解説 :データ解析・分析手法 - NTTコム リサーチ | NTTコム オンライン
深層強化学習
深層強化学習とは、強化学習とディープラーニングを組み合わせた学習方法。強化学習と深層強化学習では、「ある状態において、最適な行動を学ぶ」という点では同じだが、深層強化学習における学習では、エージェントが行動を決定する手掛かりとして「ニューラルネットワーク」が用いられる。
代表的な手法に、Deep-Q-Network(DQN)がある。DQNは、Q学習における行動価値関数(Q関数)を、畳み込みニューラルネットワークに置き換えて近似したものである。
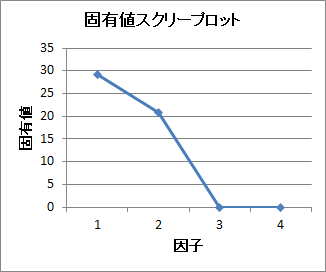
スクリープロット
ある成分や因子に対して、それに対応する固有値を降順でプロットしたグラフのこと。 因子や成分の寄与の大きさの指標となる。
このグラフをもとに成分数や因子数を決定する方法がある。主成分分析や因子分析、多次元尺度法で出力される。
スパースモデリング
スパースは「希薄」「まばら」という意味。スパースなデータから学習する手法となり、ラッソ回帰によりフィッティングを行う。
正則化
学習時に用いる式に項を追加することによってとりうる重みの値の範囲を制限し、過度に重みが訓練データに対してのみ調整される(過学習する)ことを防ぐ役割のこと。
L1、L2正則化を用いた機械学習モデルは損失関数とパラメータの値の和を最小にするパラメータを学習する。パラメータの和を評価することでパラメータが大きくなるのを防ぎ、モデルが過学習しないようにする。
正則化なし
ただの損失関数そのものである。線形回帰においては平均二乗誤差(MAE)を使うのが一般的である。(最小二乗法)。これを最小化すればするほどフィッティングしていく。つまり、損失関数=0の時は誤差=0ということなので、完全にフィッティングしている状態(=過学習)となる。
L2 正則化
損失関数にあえて正則化項を足して過剰なフィッティングをぼやかす。このぼやかした上でなるべく上記式が最小化となるようにすることで適度なフィッティングとするのである。上記をリッジ回帰という。
L2正則化項ではフィッティングしたときの各ウエイトの2乗を足し込む。要は各説明変数xの係数の2乗の和である。(ユークリッド空間)
L1 正則化
これも基本的な考え方は同じで、正則化項がウェイトの2乗ではなく絶対値(マンハッタン距離)となる。上記をラッソ回帰という。
機械学習で「分からん!」となりがちな正則化の図を分かりやすく解説 #Python - Qiita
線形回帰
説明変数x、目的変数yの関係性において2次元であれば直線や、3次元であれば平面でフィッティングを行う回帰分析。多次元まで拡張すれば以下の数式で表される。
βは回帰係数といい、仮説検定により決定を行う。すなわちβ=0を帰無仮説として、x,yのサンプルで回帰分析をした結果、β=0.4という数値が得られたとする。この時β=0.4というのはβ=0に対してどれほどありえる数値なのか?という検証を行う。もし、β=0に対してβ=0.4が誤差の範囲内であれば、β=0.4は偶然そうなったと言えるため有意な数値と言えない。(つまり、説明変数の係数は0が妥当であり、回帰しているといえない。)しかし、これが誤差の範疇を明らかに超えるのであれば、それは偶然ではなく有意な数値として言えるため、回帰係数が妥当な値であることになり、結果、説明変数xは目的変数yへ寄与していることが言えるのである。
t検定についての考え方を整理してみた - 一生旅行生活してえ
ソフトマックス関数
入力データ(=ベクトル)内の複数の値(=ベクトルの各成分)を0.0~1.0の範囲の確率値に変換する関数である。この関数によって出力される複数の値(=ベクトルの各成分)の合計は常に1.0(=100%)になる。シグモイド関数はソフトマックス関数の一種である。
損失関数
作成したモデルと実際のデータとの誤差を表す指標で、小さいほどデータに対してモデルがフィッティングしていることを表す。線形回帰においては平均二乗誤差(MAE)を使うのが一般的である。(最小二乗法)
た~
多重共線性
重回帰モデルにおいて、説明変数の中に、相関係数が高い組み合わせがあることをいう(例: 身長と座高)。重回帰分析の際、説明変数を増やすほど決定係数が高くなりやすいために、より多くの説明変数を入れ、多重共線性を起こす可能性がある。
例えば、100m走のタイムについて身長と座高を説明変数として重回帰分析を行った場合、そもそもの身長と座高において相関があるため、例えば本来は身長の高さが100m走のタイムに比例する、となるべき結果が、座高の高さが100m走のタイムに比例する、というような偽相関が導かれ、単独の影響を分離したり、正しい効果の評価が行えなくなる。
畳み込みニューラルネットワーク
「ニューラルネットワーク」の一種。ニューラルネットワークは通常3層程度で構成されているが、さらに多くの層(深い層)から構成されるものが「ディープニューラルネットワーク」であり、CNNはディープニューラルネットワークの一つとなる。
CNNでは「畳み込み層」「プーリング層」「全結合層」の3つの層を組み合わせて構成されている。
畳み込み層
畳み込み層の役割は、画像内の局所的な特徴量の抽出である。画像には隣接するピクセル間の関係性があり、エッジや色の変化といった局所的な特徴を検出する。これにより、画像内の情報を保持しつつ、高度な特徴の抽出が可能となる。
プーリング層
プーリング層の役割は移動不変性の付与となる。プーリング層では、畳み込み層で抽出された特徴が移動しても影響を受けないようにする。例えば、犬と猫を画像データから判別する場合、本来であればそれぞれの動物が画像内のどこにいても判別には影響を与えない。しかし、畳み込み層で出力された特徴だけでは、学習した画像の左側に動物がいた場合に、右側に動物がいる場合の判別がうまく行えなくなる。そこで、プーリング層では犬や猫といった特徴を維持しながら位置に関する情報を削ぎ落とすことで、重要な情報を保持する役割を果たしている。
全結合層
全結合層では、畳み込み層やプーリング層での演算で抽出した特徴量から、全情報を取りまとめることで画像の認識ができるようになる仕組み。最終的に出力層に予測や分類の結果を出力する。
何層も積み重ねることにより複雑で有効な特徴量を利用した処理が可能となる。

その他の知識について
G検定|ディープラーニングの手法|CNN・畳み込み層・プーリング層などを分かりやすく解説 | ひよっこデータサイエンティストのお勉強
ダミー変数
データには量的データと質的データの2つに分かれる。前者は身長や速度といった数値的に表現が可能なもの、後者は男女や好き嫌い、といった定性的な内容となるものである。前者はそのまま定量値として利用が可能だが、後者をデータとして扱うために0又は1で表現した変数のことをダミー変数という。
例えば男=0,女=1のように定義をしたり、以下のような配列での定義を行う。
また、このダミー変数に変換することをOne-Hotエンコーディングという。
探索木
探索木(search tree)とは、データ構造の一つである木構造のうち、値の探索に適した性質を備えたもの。どの要素(ノード)の値も、左側のすべての子ノードの値より大きく、右側よりは必ず小さくなるよう調整したもの。
深さ優先探索
あるノードの末端まで探索をしてからノードを遡って、隣のノードを同様に末端まで探索を行いながら探索を行っていく方法。
目的のノードがなくても1つ手前のノードに戻って探索し直すだけなので、辿ったノードを記憶する必要がなく多くのメモリを必要としない一方で一般的に、幅優先探索より目的のノードに辿り着くまでに時間を要する
幅優先探索
ノードから繋がっている隣のノードを順番に全て探索を行ってから、後続のノードの探索を開始して、探索すべきノードが見つかるまで処理を行うというもの。
最短距離でゴールにたどり着くことができるが、探索したノードを記憶するために、複雑な探索木になればなるほど、多量のメモリを要する。
敵対的生成ネットワーク
GANsは生成ネットワーク(generator)と識別ネットワーク(discriminator)の2つのネットワークから構成される。例として画像生成を目的とするなら生成側がイメージを出力し、識別側がその正否を判定する。生成側は識別側を欺こうと学習し、識別側はより正確に識別しようと学習する。このように2つのネットワークが相反した目的のもとに学習する様が敵対的と呼称される所以である。
転移学習
すでに学習が完成している既存のAIを用いて、機能が異なる別のAIを作成する手法。具体的には、AIの学習モデルを構成するいくつかの層のうち、出力層のみを削除した上で学習を行う。例えば、画像内の物体がリンゴかどうか判別できるAIの学習モデルをもとに、みかんを判別するAIを作ることなどが可能となる。
ファインチューニング
ファインチューニングは、もととなるAIの学習モデルの「重み」を調整して、新たな学習モデルを作ることを指す。これにより既存の学習モデルを用いて、ゼロから学習を行うよりも効率的にAIの精度を高めることが可能となる。
ファインチューニングでは重みの調整を行うことに対して、転移学習では出力層以外の学習モデルをそのままの状態で利用することに違いがある。
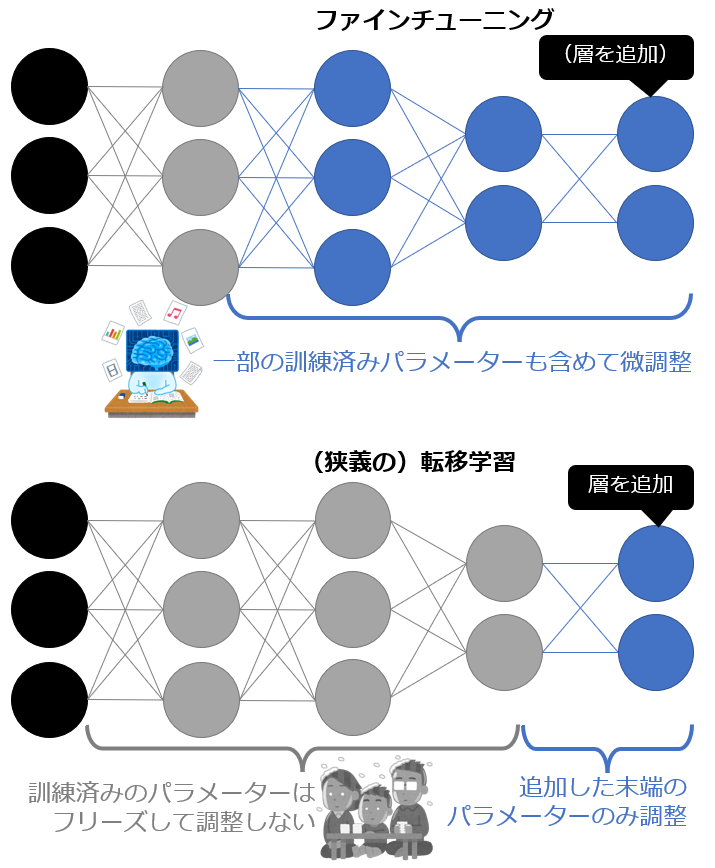
引用元:
ファインチューニング(Fine-tuning:微調整)とは?:AI・機械学習の用語辞典 - @IT
蒸留
AIの蒸留は、大規模な学習モデルをもとに、同様の機能を持ったより小さな学習モデルを開発する手法。通常のAIの学習では、大量のサンプルデータを入力してモデルの構築が行われる一方、蒸留ではサンプルデータに加えて、すでに完成している学習モデルが出力した結果も参考にすることが特徴である。
蒸留ではもととなる学習モデルによる出力結果を利用することに対して、転移学習はもとの学習モデル自体の一部を利用する点が異なる。
ドロップアウト
ニューラルネットワークにおいて、過学習を防ぐために適宜一部のノードをランダムで不活性にする手法。これを繰り返し全体的な平均を導き出すため、アンサンブル学習ともいえる。
プルーニングとの違いは?
な~
ニューラルネットワーク
人間の脳内細胞(ニューロンと呼ばれる)を数式で表した数理モデル。ニューロン内では、相互に接続されている複数のノードが存在する。それぞれのノードが発火し、信号が浅い層から深い層まで流れることで人間は物事を抽象的に分類することができる。ニューラルネットワークでは、これらの構造を数理モデルで模倣することで、データを浅い層から深い層まで分解し、膨大な情報(音声データ、画像データ)からパターンを見つけ出す。
一般的なニューラルネットワークは、情報が入力される「入力層」、情報が発信される「出力層」、その中間にある「隠れ層」の3層で構成される。
なかでもニューラルネットワークの肝となるのが、入力されたデータに対してさまざまな計算を行う隠れ層となる。隠れ層をいくつも持つことで、より複雑な問題にも対処できるようになる。

活性化関数の役割と種類についてわかりやすく解説 | AVILEN AI Trend
入力される信号をx1,x2、出力される信号をyとおく。
上の図にある青丸はニューロン、ノードと呼ばれる。また、w0はバイアス、w1,w2は重みと呼ぶ。これらw0,w1,w2はパラメータであり、どのようなパーセプトロンであるかを表現するものとなる。
単純パーセプトロン
入力層と出力層からなるシンプルなネットワーク。入力された信号に重みを乗算した総和が計算され、その総和がある閾値を超えたときにのみ1を出力する。また、閾値を超えなかった場合には0を出力する。これにより分類が可能となる。
パーセプトロンをy=ax1+bx2と置くことで、以下のように可視化ができる。

ニューラルネットワークの起源:パーセプトロンを図解と数式、プログラムで徹底解説 – <体験型>学習ブログ by zero to one
多層パーセプトロン
入力層と出力層に加えて中間層(隠れ層)からなるネットワーク。単純パーセプトロンでは線形分類可能な問題しか解けなかったが、多層パーセプトロンにより非線形分類問題を解くことができる。
仕組みとしては単純パーセプトロンを組み合わせることで、非線形な分類が可能となる。つまり、単純パーセプトロン1つ1つは線形であっても、パラメータや範囲の調整により曲線を表現し、分類をするのである。

ニューラルネットワークの起源:パーセプトロンを図解と数式、プログラムで徹底解説 – <体験型>学習ブログ by zero to one
活性化関数
隠れ層において、個々のニューロンからの入力情報を元に出力用に加工する工程となる。例えばシグモイド関数により正規化して[0,1]で出力する、というような場合である。
tanh関数
あらゆる入力値を-1.0~1.0の範囲の数値に変換して出力する関数。
座標点(0, 0)を基点(変曲点)として点対称で、S字型曲線のグラフになる。つまり「tanh関数」は、「シグモイド関数の拡張バージョン」ともいえる活性化関数である。
しかしシグモイド関数の微分係数(Derivative: 導関数の出力値)の最大値は0.25と小さいため、勾配が小さくなりがちで学習に時間がかかるという問題があった。そのため学習がより高速化するように、最大値が1.0となる「tanh関数」がよく採用されるようになった。
ReLU関数
ReLU(Rectified Linear Unit、「レルー」と読む)とは、関数への入力値が0以下の場合には出力値が常に0、入力値が0より上の場合には出力値が入力値と同じ値となる関数である。
座標点(0, 0)を基点として、ランプ(ramp: 例えば高速道路に入るための上り坂などの「傾斜路」のこと)型曲線のグラフになるため、「ランプ関数」(ramp function)とも呼ばれる。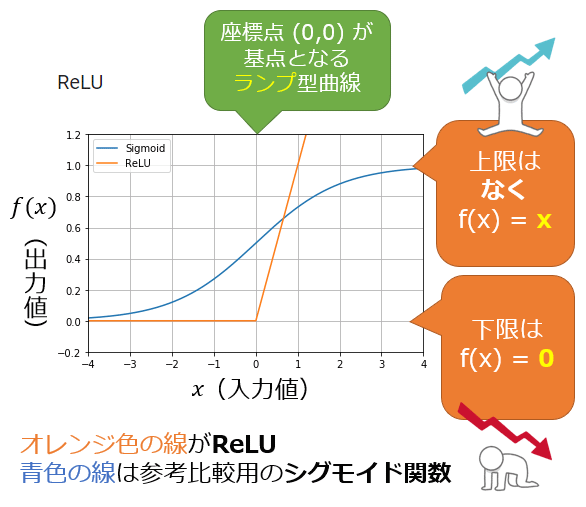
引用元:
[活性化関数]ReLU(Rectified Linear Unit)/ランプ関数とは?:AI・機械学習の用語辞典 - @IT
シグモイド関数を重ねれば重ねるほど勾配の値は小さくなっていくため、微分係数の最大値が1.0(範囲は0.0か1.0)である「ReLU」(本稿で解説)が使われるようになった。
ネオコグニトロン
ネオコグニトロンはパターン認識を行う多層神経回路モデルであり、80年代に福島邦彦により提案された畳み込みニューラルネットワークである。
畳み込みの手法を導入する以前のコグニトロン(「教師なし学習」を行う多層神経回路)では位置ずれや変形の影響を受けやすかった。 このため、形の類似性だけに基づいてパターン認識することを目的としてネオコグニトロンが開発された。
は~
白色化
各特徴量を無相関化し、かつ、平均0・標準偏差1にすること。
次元圧縮・主成分分析の一種と考えられる。
バッチ正規化
ミニバッチにおける入力データを正規化し、学習効率を向上する方法。これによりデータの偏りをなくしていくため、学習が早くなり過学習を防止できる。
汎化能力・性能
教師あり学習において未知のデータに対して予測・識別をする能力およびその性能。
交差検証法などにより学習データと検証データを活用して精度を高める必要がある。
評価指標
RMSE(もしくはMSE) (Root Mean Square Error)
二乗平均平方根誤差(RMSE)、もしくはルートが無いものは平均二乗誤差(MSE)となる。

は実測値、
は予測値である。
誤差が1より大きいと2乗されるため累計誤差に大きく影響してしまう。逆に1以下であれば影響は小さくなる。
MAE(Mean Absolute Error)
平均絶対誤差。

は実測値、
は予測値である。
各行で実測値から予測値をマイナスし、それが常に正の値になるように絶対値を取る。その後、すべての絶対誤差の平均を求める。
この指標ではすべての誤差は同じ重みとなる。
RMSLE(Root Mean Squared Logarithmic Error)
予測値と実測値の対数差の二乗の総和の平均値のルートをとったもの。
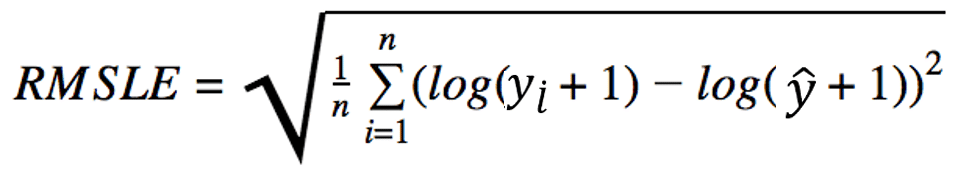
(n = 件数 、y = 実測の値、ŷ =予測の値)
logの部分は分数でとなるため、予測と実測の比率に着目したい場合に利用する。
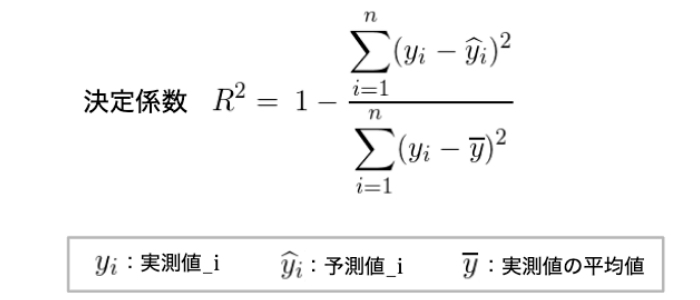
Rの2乗
予測値の残差平方和と平均値との偏差平方和の割合より算出する。通常は0~1の値を取り、1に近いほど精度が高いモデルとなるが、1に近すぎる場合は過学習をしている可能性がある。
プーリング
入力画像のある範囲のウィンドウの数値から一つの数値を取り出し、画像データを小さくまとめる処理。畳み込み層のあとに配置されると、畳み込み層の出力に対してウィンドウ内の最大値や平均値などを計算する。この際、数字の組が多少異なっても、プーリングによって同じ結果が出力される。つまり、画像の平行移動などがあっても影響を受けることがないように、あまり重要ではない位置に関する情報を削ぎ落とす役割を果たす。
物体検出
バウンディングボックス
画像や映像の中の物体を囲む長方形の枠のこと。
R-CNN
画像の中で物体の候補を囲む領域(バウンディングボックス)を約2,000個抽出して分類する手法。探し出したバウンディングボックスそれぞれに対して畳み込みとプーリングを繰り返し、その候補が物体であるかどうかを判定する。
2,000個の物体候補を探して、そのあと一つひとつに畳み込みとプーリングを繰り返していくというステップを踏むため、欠点として処理時間が非常に遅いこと、メモリを大量に消費することがある。
YOLO
You Only Look Onceの略で、処理速度が非常に早い物体検出アルゴリズムの1つ。YOLOの物体認識の手法は予め画像全体を正方形のグリッドに分割しておき、それぞれのグリッドに対象となる物体が含まれているかどうかを判定する。
対象物の候補を約2,000個探して個別に分析していくR-CNNと異なり、YOLOはYou Only Look Onceの名前の通りまず画像全体を見回して、対象物がなさそうな背景部分をばっさりカットする。そして、バウンディングボックス設定と分析を同時に行うので分析速度が格段に高速でリアルタイムの物体検出が可能となる。
SSD
SSDはSingle Shot MultiBox Detectorの略で、精度はFaster R-CNNと同等程度、処理速度も早いという特徴を持っており、YOLO同様、リアルタイムでの物体検出が可能。
SSDでは、画像の畳み込みを行う際に読み込むグリッドのサイズをずっと小さくして、検出した物体候補に対して複数のサイズの領域で枠取りをする。大きさと縦横比が異なる複数種類の領域を準備して正確なバウンディングボックスの位置を予測するのが大きな特徴。
ベイズの定理
ある事象に関連する可能性のある条件についての事前の知識に基づいて、その事象の確率を記述するものである。事象Aが起こるという条件下で事象Bが起こる条件付き確率は以下の数式で表される。
その逆に、事象Bが起こるという条件下で事象Aが起こる条件付き確率は以下の数式で表される。
これらを整理すると以下の数式(ベイズの定理)が成り立つ。
条件付き確率の具体例
1.サイコロをふったところ、出目を見落としたしまったが、偶数が出たと友人が言っていた。この時4以上である確率はどうなるか?
つまり、事象A(偶数)が起こるという条件下で事象B(4以上)が起こる条件付き確率となる。P(A)は1/2、P(A∩B)は1/3なので、条件付き確率P(B|A)は
となる。
ここで、同様に考えて事象B(4以上)が起こるという条件下で事象A(偶数)が起こる条件付き確率も2/3となる。つまり、ベイズの定理より以下が成立する。
2.とある病気にかかっているか判定する検査について考える。この病気は 10 万人に一人が罹患している。「病気なのに陰性と判定してしまう確率(偽陰性)」「病気でないのに陽性と判定してしまう確率(偽陽性)」はともに 0.01 であるとする。太郎さんが陽性と判定されたとき、本当に病気にかかっている確率を求めよ。
つまり、事象A(陽性の判定)が起こる条件下で事象B(本当に病気にかかっている)が起こる条件付き確率である。
P(A)は真陽性(病気かつ正しい判定)+偽陽性(健康かつ誤った判定)なので、1/100,000*0.99+99,999/100,000*0.01=0.0100098となる。
P(A∩B)は陽性判定かつ本当に病気にかかっている状態、つまり真陽性の状態なので、1/100,000*0.99=0.0000099となる。
以上より、条件付き確率は
つまり、陽性と判断されても本当に病気である確率は 0.01%ということなのである。
方策勾配法
強化学習は機械学習の一部門で、エージェントが環境と相互作用しながら、報酬を最大化するための行動を学習するもの。そして、方策勾配法は、この**エージェントの方策(行動を取る確率)**を直接最適化する手法の一つである。
数学的に言うと、方策はある状態での行動の確率を示すもので、方策勾配法はこの方策のパラメータを更新して、期待される報酬を増加させることを目指す。具体的には、方策の勾配方向にパラメータを更新することで、エージェントがより良い行動を選択する確率を上げる。
1.まず初期方策を定義する。
2.初期方策で一連の行動をする。
3.行動の結果から、初期方策を評価。
4.評価値と方策から「方策勾配定理」を用いて、方策を更新
5.もう一度、一連の行動をする
6.3から繰り返し
ボルツマンマシン
回帰型ニューラルネットワークの一種。
データを入力層からと出力層への一方向の流れで処理をして分類するパーセプトロンと異なり、ニューロンが相互間でランダムに数回データ処理して、規則性や動作を確率で表現するモデルとなる。
つまりボルツマンマシンではデータの入力層・出力層に対して一方通行の流れはなく、ユニットの出力が何らかの経路で自身へ再び入力ネットワーク(回帰型ネットワーク)となる。
ただし、設けたニューロンが相互間でデータ処理をランダムに複数回繰り返すので、計算が複雑になりデータ処理に長い時間がかかってしまう。
機械学習を学ぶ上で知っておきたい「ボルツマンマシン」についてまとめ | AIZINE(エーアイジン)
制限付きボルツマンマシン
ボルツマンマシンでは計算が複雑で処理に時間がかかるため、制限付きボルツマンマシンではニューロンを入力層と中間層の二層構造にして、同じ層同士でのつながりをなくしている。この二層構造にて双方向の情報やり取りが発生する。
深層信念ネットワーク
制限付きボルツマンマシンを複数組み合わせた生成モデル。二層構造となる制限付きボルツマンマシンを組み合わせて多層化したもの。
ま~
マルコフ過程
経過には関係なく、現在の状態によって次に起こる事象の確率が決まる過程のこと。つまり「ひとつ前の状態にのみ依存する条件付確率」
ミニマックス法
将棋やオセロなどの二人零和有限確定完全情報ゲームを前提とする。「自分にとっての最善手は、相手にとっての最悪手」と言った考えに基づいて、ツリー構造(ゲーム木)を元に先読みをして最善手を探索する方法。
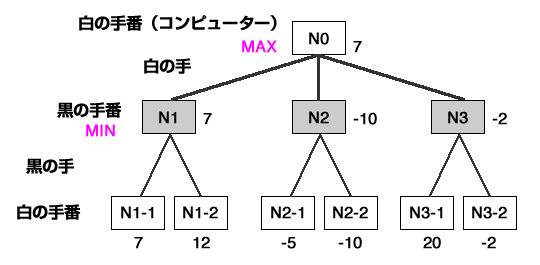
web帳 | 5分で覚えるAI Minimax(ミニマックス)法とalpha-beta法
上記の図において、まずN1-1、N1-2の状態から考える。この時、評価値は7もしくは12となるが、相手(黒)からすれば12という高い評価を与えるわけにはいかないので、N1-1の手を選択する。つまり、ここにおいてN1は評価値7が確定する。
同様に考えてN2の場合は-10、N3の場合は-2となる。ここで、自分(白)は最も高い評価値を選択していきたいので、7,-10,-2の中での最善手、つまりN1の手を選択することになる。
αβ法
ミニマックス法が理論上最善手を探すアルゴリズムとなっているのだが、計算に時間がかかりすぎるという問題がある。そのため、絶対に採用されない手をそれ以上読み込まないことで枝刈りを行い、効率向上させる。これをalpha-beta法という。
上記の図をもとにすると、N1で7が確定したあと、N2-1で-5であることがわかった時点で、N2が7より小さいことが確定するため、N2-2の探索は不要となるので、ここで打ち切ることができる。このときの下限値(今回でいうと7)をβ値という。
つまり、最大のスコアを選ぶ過程(今回でいうとN1,N2,N3)において、既に出現した評価値より低い値のノードが出たら、それ以降の探索を行わないのがβカットである。
逆に最小スコアを選ぶ過程において、既に出現した評価値より高い値のノードがでたら、それ以降の探索を行わないのがαカットである。
モンテカルロ木探索
モンテカルロ法を使った木の探索。シミュレーションを繰り返し、その平均的な結果が良い候補手を優先的に探索するアルゴリズムである。モンテカルロ木探索は汎用なアルゴリズムであり、囲碁やHexといったさまざまなゲームで有効性が確認されてきた。特に囲碁では初めてプロ棋士に勝ったプログラムAlphaGoでの探索に採用された。
や~
尤度
想定するパラメーターがある値をとる場合に、観測している事柄や事象が起こりうる確率のこと。
例えば表が出る確率が0.4のコインにおいて、コインを投げて3回連続表が出る確率は0.4^3=0.064となり、これが尤度となる。
最尤推定
最もらしい尤度を推定する方法。あるコインにおいて、表が3回、裏が1回出た場合、このコインにおける表が出る確率、つまり尤度pは0.75と言えそうである。解析的に解くと以下の通り。
表が出る確率がpの時、裏が出る確率は(1-p)となるため、上記事象L(p)は以下の式で表される。
これを微分して最大化条件を求めると
以上よりP=0.75が求まる。
ら~
ランダムフォレスト
「決定木」と「アンサンブル学習(バギング)」という2つの手法を組み合わせたアルゴリズム。機械学習の「分類」「回帰」といった用途で用いられる。「決定木」単体で使うよりも高い精度を出せる点が特徴。なお、ランダムフォレストをさらに多層化したアルゴリズムは「ディープ・フォレスト(Deep Forest)」と呼ばれる。
1.決定木のモデルをたくさん用意し、それぞれに問題の予測をさせる。
2.決定木が出した予想を集計する。
3.多数決(一番予測されたものの多かった答え)の結果がランダムフォレストの予測となる。
分類問題であれば多数決、回帰問題であれば平均値を用いる。
1、2において重複ありでサンプルを抽出し複数に分散して、並列で学習を行い統合することをバギングという。
https://zero2one.jp/ai-word/random-forest/
リカレントニューラルネットワーク (RNN)
文章解析においては、前後の文脈や過去との整合性が必要となる。そのため、各入力データの独立性を前提としていた従来のニューラルネットワークとは異なり、隠れ層における出力結果をさらに中間層の入力とすることで文章を精緻化する。例えば、「私は 昨日」だけでは何の事かわからないが「私は 昨日 本を」までくればその後には「読みました」が続くであろう。つまり、「私は」「昨日」「本を」が関連していることを読み解くのである。
Bidirectional RNN
中間層の出力を、未来への順伝播と過去への逆伝播の両方向に伝播するネットワークである。BRNN では、学習時に、過去と未来の情報の入力を必要とすることから、運用時も過去から未来までのすべての情報を入力してはじめて予測できるようになる。
GRU (Gated Recurrent Unit)
長期記憶を可能にした再帰型ニューラルネットワークの一つである。通常の RNN は勾配を逆伝播することによって学習を行うが、状態 t が長くなると、その勾配が消失したりあるいは発散したりすることが指摘された。LSTM や GRU は勾配消失問題を解決するために提唱されたアーキテクチャである。
更新ゲートとリセットゲートの2つのゲートが存在し、それぞれ異なる役割を果たしている。
更新ゲート:過去の隠れ状態をどの程度保持するかを決定するゲート。更新ゲートが閉じていると、過去の情報が保持され、勾配消失問題が緩和される。
リセットゲート:過去の隠れ状態が現在の隠れ状態へどの程度影響を与えるかを制御するゲート。リセットゲートが開くことで、無関係な過去の情報が破棄され、新しい情報の学習に焦点が当てられる。
GRUでは、更新ゲートとリセットゲートの働きにより、過去の隠れ状態を効果的に利用しながら、新しい情報を学習することが可能となる。この機構により、GRUはRNNの勾配消失問題に対処し、時系列データや自然言語処理タスクで優れた性能を発揮する。
ロジスティック回帰分析
目的変数が0と1からなる2値のデータ、あるいは0から1までの値からなる確率などのデータについて、説明変数を使った式で表す方法のこと。
◆ロジスティック回帰分析の利用シーン
・顧客がどのような理由で商品を購入するのか可能性を分析する
・ある病気になるリスクを、生活習慣などの複数の要因から予測する
・どのチャネルの広告配信が最も効果的かを調べる
ロジスティック回帰分析とは?用途、計算方法をわかりやすく解説!-GMOリサーチ
オッズ
ある事象が発生する確率としない確率の比で表されます。ある事象が発生する確率をpと置くと下記数式で表される。
例えばサイコロで1,6が出る確率は1/3なので、これのオッズを取ると、1/3÷(1-1/3)=0.5となる。ここにおいて、限りなく低い確率の事象で上記オッズを取ると0に近づき、逆に確率が高い事象の場合は∞へと発散する。(例えば1/100で発生するような事象で計算するとオッズは0.010...という値になる。逆に99/100で発生する事象であればオッズは99となる。)
ロジスティック関数
このオッズの対数を取ったものをロジットと呼ぶ。
これについてy=logit(P)とした時の逆関数をとり、P=の形にすると以下のようになる。(「ロジスティック変換」)
そしてこのときの関数を「ロジスティック関数」という。これによって何が嬉しいのかというと、元々Pは確率なので0~1の値をとり、これを元にしたオッズは0~∞の値を取るが、ロジットであれば、-∞~∞の値を取ることとなる。
ここでロジスティック関数は、y:-∞~∞に対して0~1の値を取る関数となり、シグモイド関数とも呼ばれている。
ロジスティック回帰分析のモデル式
ロジット=重回帰分析の式 となる。つまり以下となる。
これをロジスティック変換すれば確率Pに対して以下の式となる。
具体的に、A大学の合格判定をするにあたり、国語・数学・英語の点数に回帰するとする。各教科の点数により回帰式の値が2.1となった場合、となるのである。
わ~
A~G
Bag-of-Words
文章内の単語の頻度を用いて文章を数値ベクトルに変換する方法。
ある文章内で「犬」や「猫」の単語が高頻度であれば、ペットに関する内容と推察できたり、「野球」や「サッカー」の単語が高頻度であれば、スポーツに関する内容と推察できる。同様に、BoWでベクトル化した文章は、単語頻度を基に文書分類タスクなどに応用が可能となる。
BERT
Bidirectional Encoder Representations from Transformersを略した自然言語処理モデルであり、2018年10月にGoogle社のJacob Devlin氏らが発表した。日本語では「Transformerによる双方向のエンコード表現」と訳す。
BERTの特徴として、「文脈を読めるようになったこと」が挙げられる。Transformerと呼ばれるアーキテクチャ(構造)を組み込むことによって、文章を文頭・文末の双方向から学習し、文脈を読めるようになった。
Cutout
画像データ拡張の手法。学習中に正方領域をマスクすることにより、モデルは欠損した情報やノイズが存在する状況に対しても頑健性を向上させることができる。

DQN(Deep Q-Network)
Q学習にニューラルネットワークの考え方を含めたもの。
最適行動価値関数をニューラルネットを使った近似関数で求め、ある状態”_”のときに行動ごとのQ値を推定できれば、一番いいQ値の行動=取るべき最善の行動がわかるという仕組み。ある状態”sₜ”を入力し、行動”a”が出力層のノードとなるようなニューラルネットワークを使用して”Q(sₜ,aₜ)”の値を計算する。
GLUE
自然言語処理における文章に書かれている内容などを正確に理解することによって解かれる言語理解タスクをまとめたベンチマーク。
H~L
ILSVRC
2010年から始まった大規模画像認識の競技会。(2017年に終了)。2012年にAlexNetというCNNを使用したモデルが優勝し、ディープラーニングが注目を浴びるきっかけとなった。代表的なアーキテクチャは以下の通り。
- AlexNet
- VGG
- GoogleNet
- ResNet
- DenseNet
- MobileNet
画像分類の6つの代表的なアーキテクチャの特徴まとめ | AI研究所
k-近傍法
データをグループ分けするにあたり、対象とするあるデータがどのグループに含まれるかを周囲のデータの多数決で推測するという手法。以下の図において、☆に近い点を近い順に任意の数、k個だけ選ぶ。その選んだ点に最も多く含まれているグループに☆も分類されると考える。(つまり、今回の例で言えば★は青グループに分類する。)

k-means法
データを k 個にグループ分け (クラスタリング) するアルゴリズム。
1. 各データにランダムなクラスタを割り当てる。
2. クラスタごとに重心を求める
3. 各データを、クラスタ重心が最も近いクラスタに変更
4. 全てのデータのクラスタが変化しなくなるまで、2, 3 を繰り返す
潜在的ディリクレ配分法(LDA)
トピックモデルの手法。複数のクラスタに分類することが可能。なお、トピックモデルは、自然言語処理の分野で用いられる統計的潜在意味解析の一つで「言葉の意味」を統計的に解析していく手法。
LogLoss(Logarithmic Loss)
二値分類や多クラス分類のタスク(問題)に対する評価指標の一つで、機械学習モデルによる予測が正解にどれくらい近いかを表す値である。0.0(=近い)~∞(=遠い)の範囲の値になり、0.0に近づくほど(つまり数値が小さいほど)より良い。
定義式は以下の通りである。
y : 正例のラベル(1が正例で、0が負例)
p : 予測結果(正例の確信度)
正例の確率を高く予測したものが間違っていると(負例の確率を高く予測したものが間違っていると)ペナルティが大きく与えられるようになっている。
具体例として、N=1において、y=1、p=0.8の時、つまり正例において正例を80%の信頼度で予測する場合のloglossは約0.22となる。
他方、y=0、p=0.9の時、つまりに負例おいて正例を90%の信頼度で予測する場合のloglossは約2.30となる。
つまり自信満々な予測が外れるほど値が大きく出るようになっている。
LSTM(Long Short Term Memory)
文章解析においては、時系列が古い情報でも文章としてはそれを元に組み立てることがあるため、古い情報だからといって軽視してはいけない。
例えば「私は野球が好きです。ところで今月から新しい趣味としてギターを始めたのですが…」といった文章があった場合、「野球が好き」という情報はどんどん文章が進むに連れて忘れ去られてしまっていく(重みが小さくなっていく)。そのため、その続きが本来「ギターも野球と同じくらいハマりました」となるべきであっても、「野球好き」の情報が失われるとこのような文章を出力することができなくなってしまうのである。
これを解消する手段の1つとしてあるRNNにおいては、時系列の古いデータほど勾配消失するという問題を抱えていた。そのためLSTMにては記憶するセルを保持し、記憶セル(CEC)に必要なデータを残しながら計算を行うことで、勾配消失問題を解決する。
M~R
OpenPose
カーネギーメロン大学(CMU)の Zhe Caoら が「Realtime Multi-Person pose estimation」の論文で発表した、深層学習を用いて人物のポーズを可視化してくれる手法。
OpenPoseは、静止画を入力するだけで人間の関節点を検出することが可能。さらにGPUなどの高性能プロセッサを使えば動画像内に複数人の人物がいても、リアルタイムに検出することも可能となる。
Pix2Pix
入力画像から特定の別の画像を出力するアプローチでGANベースのアーキテクチャになる。
Q学習
状態価値関数V→行動価値関数Q
行動価値関数(Q関数)
【Q学習入門】強化学習におけるQ学習を数式なしでわかりやすく解説 - TechTeacher Blog
【考え方を理解しよう】強化学習の状態価値関数と行動価値関数を解説 - DXコンサルの日進月歩奮闘記
ROC曲線
受信者操作特性(じゅしんしゃそうさとくせい、英 Receiver Operating Characteristic, ROC)
検査や診断薬の性能を2次元のグラフに表したもの。当該検査で異常と正常を区別するカットオフポイントごとに真陽性率(=TPF)と偽陽性率(=FPF)を計算し、縦軸にTPF、横軸にFPFをとった平面にプロットして線で結んで表す。
なお、真陽性率と偽陽性率の定義は以下の通りである。
真陽性率は真陽性÷(真陽性+偽陰性)
偽陽性率は偽陽性÷(偽陽性+真陰性)

【わかりやすく解説】混同行列の概要をかみくだいて説明します - DXコンサルの日進月歩奮闘記
ここで、検査基準(しきい値)を緩くすればガバガバ判定となり、真陽性率も偽陽性率も100%(=1.0)となる。逆に厳しくすれば全く陽性判定されなくなるので、0%となる。これらのしきい値をスライドさせていく中で以下のようなグラフが描けるであろう。

基本的にグラフは逓減型になると言える。というのも、きちんと判定できる水準であれば、しきい値が多少厳しくても陽性を洗い出してくれる(→100%に近くなる)からである。
なお、ROC曲線を作成した時に、グラフの下の部分の面積をAUC(Area Under the Curve)とよぶ。AUCは0から1までの値をとり、値が1に近いほど判別能が高いことを示す。
S~Z
TF-IDF
TFとIDFの2つの指標をかけあわせて単語の重要度を図る手法。
tf-idf値=(ある文書における、ある単語の出現頻度)
×(ある単語の文書間でのレア度)
tf(Term Frequency)は「単語の出現頻度」を表す。これは単語の出現回数をその文書内にある単語の数で割って算出する。
idf(Inverse Document Frequency)は「単語の出現のまれさ」「単語のレアさ加減」を示す。
Transformer
自然言語などの時系列データを扱って翻訳やテキスト要約などのタスクを行うべく設計されているのは回帰型ニューラルネットワーク (RNN)と同様だが、Transformer の場合、時系列データを逐次処理する必要がないという特徴がある。たとえば、入力データが自然言語の文である場合、文頭から文末までの順に処理する必要がない。このため、Transformer では 回帰型ニューラルネットワークよりもはるかに多くの並列化が可能になり、トレーニング時間が短縮される。
Attention
文中の単語の意味を理解するのにどの単語に注目すればいいのかを表すスコア、もしくはそれを出す機構。入力されたデータに重み付けをして重要性を考慮したベクトル量として出力する。例えばある画像が入力されて画像の説明を出力するとき、Attention機構は既に生成された単語のコンテクスト情報を前の隠れ層から受け取り、次に画像のどこに注目すべきなのかを推論する。
BERT
2018年にGoogleが開発したもの。
文脈を考慮した分散表現を生成でき、BERTではAttentionにより離れた位置にある情報も適切に取り入れることができるため、文脈を深く考慮したような処理が可能となっている。
t-SNE
高次元データを2次元や3次元に落とし込むための次元削減アルゴリズム。通常の主成分分析(PCA)では線形分離可能な構造であることが前提となり、非線形となる場合には適用ができない。そのため、確率的(統計的)手法を用いて分布を導き出し、低次元へのマッピングを行う。
t-distributed Stochastic Neighbor Embeddingの略。日本語だと「t分布型確率的近傍埋め込み法」となる。
U-NET
Olafらによって生物医学のために開発された、セマンティックセグメンテーション用のエンコーダとデコーダから成るモデル。エンコーダでは入力された画像を何度か畳み込み、その画像の特徴を抽出する。デコーダではエンコーダによって抽出された特徴を受け取り、逆畳み込み(deconvolution)と呼ばれる通常の畳み込みと逆の処理を行い、入力画像と同じサイズの確率マップを出力する。
ここで、エンコーダの特徴マップをデコーダの特徴マップに接続する手法を「スキップ接続」という。
waveNet
音声波形からサンプリングしたデータをDNN(ディープニューラルネットワーク)で処理することで、自然な発音に近い声を合成する技術。